
I read found an excellent article about System Design in Educative.io. Now I want to make notes on some important points for me to review later.
What is System Design
System design is the process of defining the architecture, interfaces, and data for a system that satisfies specific requirements. System design meets the needs of your business or organization through coherent and efficient systems. Once your business or organization determines its requirements, you can begin to build them into a physical system design that addresses the needs of your customers. The way you design your system will depend on whether you want to go for custom development, commercial solutions, or a combination of the two.
System design requires a systematic approach to building and engineering systems. A good system design requires you to think about everything in an infrastructure, from the hardware and software, all the way down to the data and how it’s stored.
System Design fundamentals
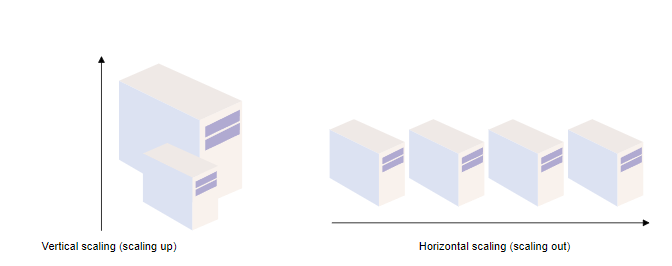
Horizontal and vertical scaling
Scalability refers to an application’s ability to handle and withstand an increased workload without sacrificing latency. An application needs solid computing power to scale well. The servers should be powerful enough to handle increased traffic loads. There are two main ways to scale an application: horizontally and vertically.
Horizontal scaling, or scaling out, means adding more hardware to the existing hardware resource pool. It increases the computational power of the system as a whole. Vertical scaling, or scaling up, means adding more power to your server. It increases the power of the hardware running the application.
Microservices
Microservices, or microservice architecture, is an architectural style that structures an application using loosely coupled services. It divides a large application into a collection of separate, modular services. These modules can be independently developed, deployed, and maintained.
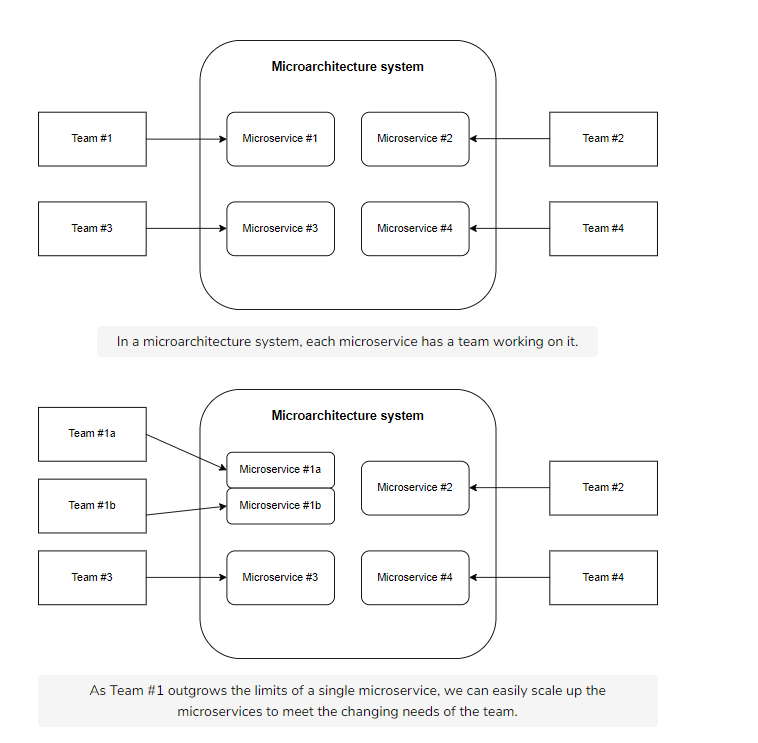
Microservices operate at a much faster and more reliable speed than traditional monolithic applications. Since the application is broken down into independent services, every service has its own logic and codebase. These services can communicate with one another through Application Programming Interfaces (APIs).
Microservices are ideal if you want to develop a more scalable application. With microservices, it’s much easier to scale your applications because of their modern capabilities and modules. If you work with a large or growing organization, microservices are great for your team because they’re easier to scale and customize over time.
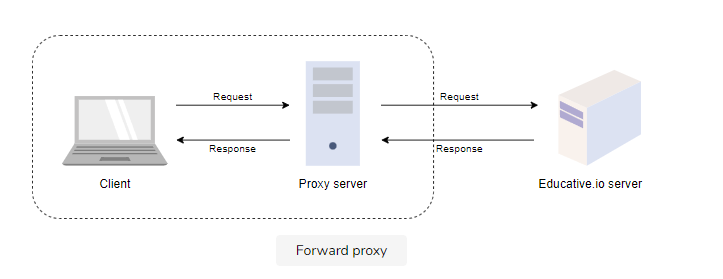
Proxy servers
A proxy server, or forward proxy, acts as a channel between a user and the internet. It separates the end-user from the website they’re browsing. Proxy servers not only forward user requests but also provide many benefits, such as:
- Improved security
- Improved privacy
- Access to blocked resources
- Control of the internet usage of employees and children
- Cache data to speed up requests
Whenever a user sends a request for an address from the end server, the traffic flows through a proxy server on its way to the address. When the request comes back to the user, it flows back through the same proxy server which then forwards it to the user.
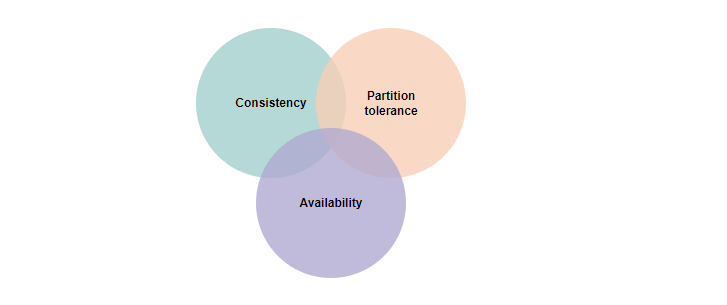
CAP theorem
The CAP theorem is a fundamental theorem within the field of system design. It states that a distributed system can only provide two of three properties simultaneously: consistency, availability, and partition tolerance. The theorem formalizes the tradeoff between consistency and availability when there’s a partition.
Redundancy and replication
Redundancy is the process of duplicating critical components of a system with the intention of increasing a system’s reliability or overall performance. It usually comes in the form of a backup or fail-safe. Redundancy plays a critical role in removing single points of failure in a system and providing backups when needed. For example, if we have two instances of a service running in production and one of those instances fails, the system can failover to another one.
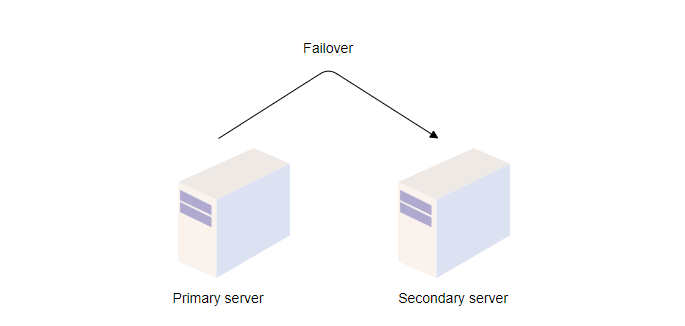
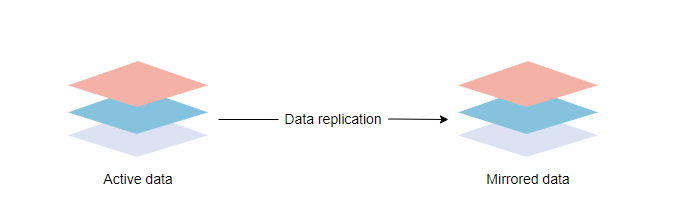
Replication is the process of sharing information to ensure consistency between redundant resources. You can replicate software or hardware components to improve reliability, fault-tolerance, or accessibility. Replication is used in many database management systems (DBMS), typically with a primary-replica relationship between the original and its copies. The primary server receives all of the updates, and those updates pass through the replica servers. Each replica server outputs a message when it successfully receives the update.
Storage
Data is at the center of every system. When designing a system, we need to consider how we’re going to store our data. There are various storage techniques that we can implement depending on the needs of our system.
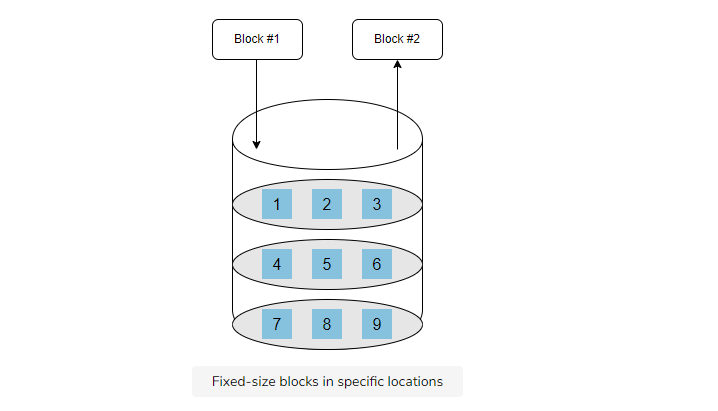
Block storage
Block storage is a data storage technique where data is broken down into blocks of equal sizes, and each individual block is given a unique identifier for easy accessibility. These blocks are stored in physical storage. As opposed to adhering to a fixed path, blocks can be stored anywhere in the system, making more efficient use of the resources.
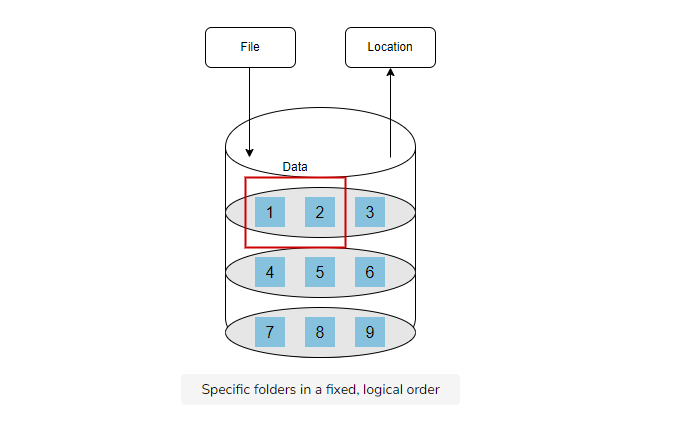
File storage
File storage is a hierarchical storage methodology. With this method, the data is stored in files. The files are stored in folders, which are then stored in directories. This storage method is only good for a limited amount of data, primarily structured data.
Object storage
Object storage is the storage designed to handle large amounts of unstructured data. Object storage is the preferred data storage method for data archiving and data backups because it offers dynamic scalability. Object storage isn’t directly accessible to an operating system. Communication happens through RESTful APIs at the application level. This type of storage provides immense flexibility and value to systems, because backups, unstructured data, and log files are important to any system. If you’re designing a system with large datasets, object storage would work well for your organization.
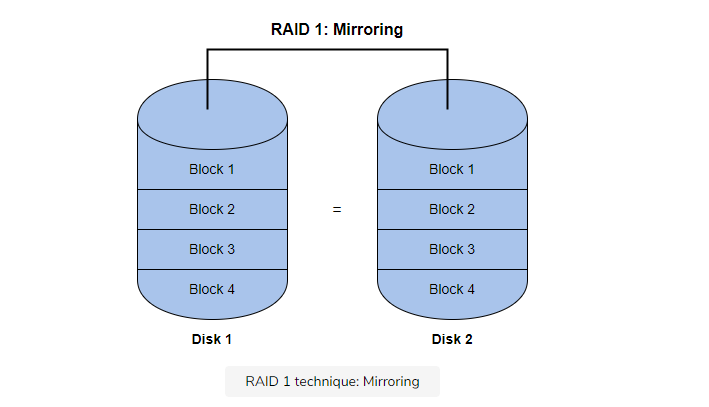
Redundant Disk Arrays (RAID)
A redundant array of inexpensive disks, or RAID, is a technique to use multiple disks in concert to build a faster, bigger, and more reliable disk system. Externally, a RAID looks like a disk. Internally, it’s a complex tool, consisting of multiple disks, memory, and one or more processors to manage the system. A hardware RAID is similar to a computer system but is specialized for the task of managing a group of disks. There are different levels of RAID, all of which offer different functionalities. When designing a complex system, you may want to implement RAID storage techniques.
Message queues
A message queue is a queue that routes messages from a source to a destination, or from the sender to the receiver. It follows the FIFO (first in first out) policy. The message that is sent first is delivered first. Message queues facilitate asynchronous behavior, which allows modules to communicate with each other in the background without hindering primary tasks. They also facilitate cross-module communication and provide temporary storage for messages until they are processed and consumed by the consumer.
Kafka
Apache Kafka started in 2011 as a messaging system for LinkedIn but has since grown to become a popular distributed event streaming platform. The platform is capable of handling trillions of records per day. Kafka is a distributed system consisting of servers and clients that communicate through a TCP network protocol. The system allows us to read, write, store, and process events. Kafka is primarily used for building data pipelines and implementing streaming solutions.
While Kafka is a popular messaging queue option, there are other popular options as well. To learn more about which messaging queue to use, we recommend the following resources:
File systems
File systems are processes that manage how and where data on a storage disk is stored. It manages the internal operations of the storage disk and explains how users or applications can access disk data. File systems manage multiple operations, such as:
- File naming
- Storage management
- Directories
- Folders
- Access rules
Without file systems, it would be hard to identify files, retrieve files, or manage authorizations for individual files.
Google File System (GFS)
Google File System (GFS) is a scalable distributed file system designed for large data-intensive applications, like Gmail or YouTube. It was built to handle batch processing on large data sets. GFS is designed for system-to-system interaction, rather than user-to-user interaction. It’s scalable and fault-tolerant. The architecture consists of GFS clusters, which contain a single master and multiple ChunkServers that can be accessed by multiple clients.
Hadoop Distributed File System (HDFS)
The Hadoop Distributed File System (HDFS) is a distributed file system that handles large sets of data and runs on commodity hardware. It was built to store unstructured data. HDFS is a more simplified version of GFS. A lot of its architectural decisions are inspired by the GFS design. HDFS is built around the idea that the most efficient data processing pattern is a “write once, read many times” pattern.
System Design patterns
Knowing system design patterns is very important because they can be applied to all types of distributed systems. They also play a major role in system design interviews. System design patterns refer to common design problems related to distributed systems and their solutions.
Databases
Relational databases
Relational databases, or SQL databases, are structured. They have predefined schemas, just like phone books that store numbers and addresses. SQL databases store data in rows and columns. Each row contains all of the information available about a single entity, and each column holds all of the separate data points. Popular SQL databases include:
- MySQL
- Oracle
- MS SQL Server
- SQLite
- PostgreSQL
- MariaDB
Non-relational databases
Non-relational databases, or no-SQL databases, are unstructured. They have a dynamic schema, like file folders that store information from someone’s address and number to their Facebook likes and online shopping preferences. There are different types of NoSQL. The most common types include:
- Key-value stores, such as Redis and DynamoDB
- Document databases, such as MongoDB and CouchDB
- Wide-column databases, such as Cassandra and HBase
- Graph databases, such as Neo4J and InfiniteGraph
Distributed Systems
Distributed systems make it easier for us to scale our applications at exponential rates. Many top tech companies use complex distributed systems to handle billions of requests and perform updates without downtime. A distributed system is a collection of computers that work together to form a single computer for the end-user. All of the computers in the collection share the same state and operate concurrently. These machines can also fail independently without affecting the entire system.
Distributed systems can be difficult to deploy and maintain, but they provide many benefits, including:
- Scaling: Distributed systems allow you to scale horizontally to account for more traffic.
- Modular growth: There’s almost no cap on how much you can scale.
- Fault tolerance: Distributed systems are more fault-tolerant than single machines.
- Cost-effective: The initial cost is higher than traditional systems, but because of their capacity to scale, they quickly become more cost-effective.
- Low latency: You can have a node in multiple locations, so traffic will hit the closest node.
- Efficiency: Distributed systems break complex data into smaller pieces.
Parallelism: Distributed systems can be designed for parallelism, where multiple processors divide up a complex problem into smaller chunks.
The cloud and System Design
Cloud computing allows access to services like storage or development platforms on-demand via internet-connected offsite data centers. Data centers are managed by third-party companies, or cloud providers. The cloud computing model not only addresses the problems that occur with on-premises systems, but also is more cost-effective, scalable, and convenient.
Different cloud providers offer different cloud services, such as storage, security, access management, and more. Cloud services give you the tools to be able to design and implement flexible and efficient systems.